浮動小数点数の文字列化アルゴリズムSchubfach
TL;DR
C++20のstd::formatやJavaのDouble#toString()のもとにもなっている1浮動小数点数の文字列化アルゴリズムSchubfachアルゴリズムの論文を読んだ。
この記事ではそのアルゴリズムを解説するが厳密な定義やエッジケースは論文をあたってほしい。
問題とその背景
浮動小数点数の文字列化がなぜ問題になるかというと、IEEE 754の浮動小数点数を10進数の小数点数に変換したときに人間にとって読みやすい表記が自明ではないからである。これは10進数の有限桁の小数点数が有限桁の2進数で表せる保証がないことが一因となっている。
よくある例を考えよう。10進数の1.2を2進数表記するとつぎのような循環小数になる2。
これをIEEE 754の倍精度浮動小数点数で表そうとすると、仮数部が52ビットなので、小数点以下53ビット以下は切り捨てる(より正確には最近接偶数丸め)。したがって、人間が端末にむかって1.2と入力すると、多くの場合はそれが上記のビット列として表され仮数部52ビットの倍精度浮動小数点数として記憶領域に格納される。さて、これを再び同じ人間に10進数で表示するときにどうすればいいだろうか。
困るのは、倍精度浮動小数点数に変換したときに、この格納されている値になり得る10進数の小数点数が 1.2 を含めて複数あるということである。実際、この倍精度浮動小数点数をそのまま10進数に戻すと以下のようになる。
これをそのまま表示するのも一案ではあるが、入力した人間からすると1.2が上記のような数値で表示されると、これは長すぎて困惑することだろう。一方コンピュータからすると、この値も1.2もあるいは1.20000000000000001も倍精度浮動小数点数にしてしまえばすべて内部的には同じ表現になってしまい、どれを表示するのが適切か不明である。
ということで、任意の浮動小数点数を人間に読みやすい10進数文字列として表示するときにどのようにフォーマットするのが適切か、というのが問題となる3。
ナイーブな解法とその欠陥
とてもナイーブな解法は小数点以下何桁かで打ち切って表示するというものである。上の例でいえばたとえば小数点以下5桁で四捨五入すれば、1.2になる。表示するときにアプリケーションで小数点以下何桁まで表示したいかを選び、あとは四捨五入するなり切り捨てるなりして表示するというのが1つの解法ではあるし、実際いくつかのアプリケーションではそれを行っている。
ただし、この解法には重大な欠陥がある。というのは、そうやって表示した10進数をふたたびIEEE 754の倍精度浮動小数点数に変換したときに同じバイナリ表記になる保証がない、ということである。たとえば、1.2000000000000001は小数点以下5桁で四捨五入すると1.2になってしまうが、この値を2進数表記すると 1.0011...00110100 となり、これは 1.2 を倍精度浮動小数点数にしたものと異なる値である。
このように、浮動小数点数→文字列→浮動小数点数と変換したときに、同じ値になっていてほしいという要求をround tripと呼ぶらしい4。ちなみに、このround tripを保証するために小数点以下何桁まで表示すべきか、という問題はすでに1968年に解かれていて、小数点以下17桁まで表示すればround tripは保証される5。
ただし、ほとんどの人間はround tripが保証されている中でもっとも桁数が小さいものを読みやすいと感じるだろう。たとえば1.20000000000000001も1.2も同じ倍精度浮動小数点数になるなら1.2を読みやすいと感じるはずだ6。
問題の定式化
以上を踏まえて、浮動小数点数の文字列化の問題をつぎのように定式化する。
有限な任意の浮動小数点数表記(以降\(fp\)とする)で\(v\)と表される正の数が与えられたとき(負の場合は同じことをやればいいので簡単のために正とする)に\(D\)進数で表記された\(d_v\)をつぎのように定義する。
- \(round\)関数を実数から\(fp\)へ変換する関数とする
- \(R = \{ x \mid round(x) = v \}\)、つまり上記の変換によって\(v\)になる値の集合とする
- \(m = \min\{len(x) \mid x \in R \}\)は集合\(R\)の各値を\(D\)進表記したときの長さ(後述)の最小値
- \(T = \{x \in R \mid len(x) = m\}\)、つまり集合\(R\)のうち\(D\)進表記した長さが\(m\)の値の集合
- \(d_v\)を集合\(T\)のうちもっとも\(v\)に近いものと定義する、ただし、そのような\(v\)が2つあった場合は\(d_v\)は偶数のものとする
なお\(fp\)はIEEE 754の単精度浮動小数点数表記や倍精度浮動小数点数表記と考えてもらって構わない。また\(D\)も一般には\(10\)であるが、ここではより一般化した形式を考える。
また、\(len\)関数で表される長さであるが、これはざっくり言えば\(D\)進数で表された値の先頭に連続する0と末尾に連続する0を取り除いた桁数ということになる。たとえば\(12000\)の長さは\(2\)だし、\(0.450\)の長さも\(2\)、\(1.23\)の長さは\(3\)となる。科学表記にしたときの仮数部の長さといってもよい。論文ではより厳密に定義しているが、アルゴリズムを理解するにはこれくらいで十分だと思う。
問題の定式化(修正版)
これはどれくらい一般的なのか知らないが、論文の著者によれば、すくなくともJavaのDouble#toString()メソッドの仕様では小さな値に1.0E-21のような科学表記がつかわれる。これがなにを意味するかというと、長さは最低でも\(2\)なわけであるから、前節の定式化において\(m=1\)の場合は、\(m=2\)となる値も候補に入れてもっとも\(v\)に近い値を選ぶべき、というのである。
たとえば\(v = 20 \cdot 2^{-1074} = 9.88\ldots\cdot10^{-323}\)であるが、前節の定式化にしたがうと集合\(T\)は
\[\begin{align} R &= \{1\cdot10^{-322}, 97\cdot10^{-324}, 98\cdot10^{-324}, 99\cdot10^{-324}, \ldots\} \\ m &= 1 \\ T &= \{1\cdot10^{-322}\} \end{align}\]となり、\(d_v = 1\cdot10^{-322}\)となる。これは科学表記だと1.0E-322となり有効数字2桁も使っていてもったいない、というわけだ。この場合は9.9E-323の方がより真実の値に近いので相応しいと著者は主張している。
個人的には細かすぎる気もするのだけれど、ともあれ、この新たな要求を言葉にすると、\(M\)を正の整数としたときに\(d_v\)はその長さが\(M\)を超えない限りにおいて\(v\)に近いものを選ぶ、となる。前節の定式化は\(M=1\)としたもので、JavaのDouble#toString()のような挙動にしたければ\(M=2\)とすればよいことになる。
修正版の問題の定式化はつぎのようになる。
有限な\(fp\)で\(v\)と表される正の数、および\(M\ge1\)が与えられたときに\(D\)進数で表される\(d_v\)をつぎのように定義する。
- \(round\)関数を実数から\(fp\)へ変換する関数とする
- \(R = \{ x \mid round(x) = v \}\)、つまり上記の変換によって\(v\)になる値の集合とする
- \(m = \min\{len(x) \mid x \in R \}\)は集合\(R\)の各値を\(D\)進表記したときの長さの最小値
- もし\(m \ge M\)なら、\(T = \{x \in R \mid len(x) = m\}\)すなわち集合\(R\)のうち長さが\(m\)の値の集合とする。そうでない場合は\(T = \{x \in R \mid len(x) \le M\}\)とする
- \(d_v\)を集合\(T\)のうちもっとも\(v\)に近いものと定義する、ただし、そのような\(v\)が2つあった場合は\(d_v\)は最終桁の値が偶数のものとする
アルゴリズムの概要
次節以降ではアルゴリズムの詳細を見ていくが、先に大まかなアイディアを説明する。これは原論文には書いていない、自分の解釈なので間違っている可能性があることに留意されたい。
前節の定式化で分かると思うが、まずround tripを保証するには浮動小数点\(v\)が表す区間に収まる範囲で\(d_v\)を選ぶ必要がある。さらにそのなかで一番長さが短いものを知りたい。さて、ここで数直線上に\(10^i, 2\cdot 10^i, 3\cdot 10^i, \ldots\)とまず目盛りをつけ、つぎに\(10^{i-1},2\cdot 10^{i-1},\ldots\)というように、粗いものから徐々に細かくして\(i\)を減らしながら\(10^i\)間隔(\(i\)は整数)の目盛りをつけていく作業を考えよう。この目盛りが細かくなるほど基本的に長さが長くなる(科学表記したときの仮数部の長さが長くなる)。
このときに\(v\)が表す実数区間には最初は目盛りが1つも打たれないが、\(i\)を減らすにしたがって、どこかで目盛りが初めて入るはずである。そしてこの初めて区間に入った目盛りの値が目指す\(d_v\)になる。もちろん初めて入る目盛が複数ということもあり得るがその場合は\(v\)に近い方を手順に従って選べばよい。
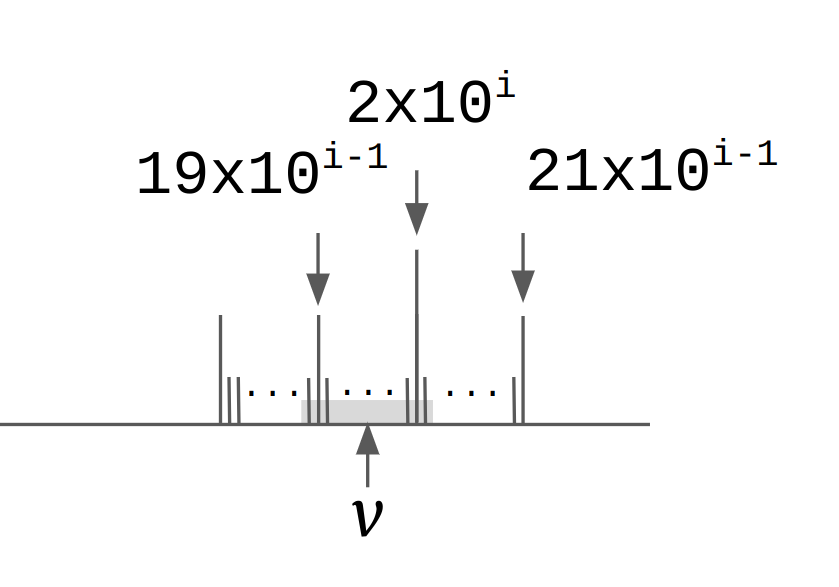
さらに、区間に入る目盛りが見つかったらそれ以上は\(i\)を小さくしなくてもいいことに注意してほしい。というのは、図からもわかるように、目盛りを細かくしたときに必ずそれより前の粗い目盛りと重なる(\(0.1\)の目盛りはそのすべてが\(0.01\)の目盛りと重なるし、とうぜん\(1\)の目盛りもすべてがそれらと重なる。\(j \lt i\)について\(10^i\)の目盛りは\(10^j\)の目盛りと重なる)ことと、目盛りが細かいほど値が長くなることから、\(10^i\)の目盛りが\(v\)が代表する区間と重なったらそれが求める\(d_v\)になる。この図でいえば、\(2\cdot 10^i\)がその区間に入っているので\(M=1\)なら文句なしにこれが\(d_v\)になる。一方\(M=2\)なら\(19\cdot 10^{i-1}\)とどちらが\(v\)に近いか調べることになる。
また、この初めて区間に打たれる目盛りはたとえば二分法で探索してもよいが、ちょっとした計算で求まる。というのは\(v\)が表す区間の幅を\(\alpha\)とすれば、\(i = \lceil\log_{10}\alpha\rceil\)のあたりを調べればよいからだ。つまり目盛り幅がちょうど\(\alpha\)になる付近を探せばかならず区間に入る目盛りが見つかるし、その目盛りの数がぎりぎり0になるかならないかになる。
したがって、\(i = \lceil\log_{10}\alpha\rceil\)を計算して、あとは目盛りが区間に入るか調べ、入らなかったら\(i\)を\(1\)小さくしてもう一度調べれば、\(d_v\)が見つかる。
以上がこのSchubfachアルゴリズムの概略である。以降ではより詳細にただし原論文ほどは厳密にせずに解説する。
前準備
さて、アルゴリズムの詳細について説明するまえにアルゴリズムが前提とする事実を確認する。
\(v\)が代表する区間\(R_v\)
浮動小数点数(\(fp\))で表せる値は離散値であり、その値の代表する実数の区間がある。具体的に\(fp\)で表した値\(v = c \cdot 2^q\) とする。ただし \(c\)は正の整数で\(1\ldots\)の形式であるとする7、\(q\)は整数。このとき\(v\)が表す区間の左端を\(v_l\)、右端を\(v_r\)とする。
ここで\(v_l\)は、\(v\)とその1つ前の\(fp\)で表せる値のちょうど中間点になる。これは数式で表すと\(v_l=c_l2^q\)とすれば
\[c_l = \begin{cases} c - 1/4 & \text{もし}v\text{が正規化数の最小値より大きなちょうど2の累乗なら} \\ c - 1/2 & \text{それ以外} \\ \end{cases}\]となる。この条件分けが発生するのは浮動小数点数を大きくしていったときにちょうど\(q\)が増えるタイミングで左側と右側で分布が異なるからである。
いっぽう \(v_r = c_r2^q\)としたときに\(c_r = c + 1/2\)となる。
以降ではこの\(v\)が代表する区間を\(R_v\)と表す。
集合\(D_i\)
任意の整数\(i\)について\(D_i\)を\(D_i = \{dD^i\}\)で表される集合とする。ただし\(d\)は任意の自然数。
このとき与えられた\(v\)について、
\[s_i(v) = \lfloor vD^{-i}\rfloor \\ t_i(v) = s_i(v) + 1\]として、
\[u_i(v) = s_i(v)D^i \\ w_i(v) = t_i(v)D^i\]とすると、この\(u_i\)と\(w_i\)が集合\(D_i\)の中で\(v\)に最も近い可能性がある2つの値である。
証明については原論文の\(\S\)6を当っていただきたいが、ざっくり説明すると、\(s_i\)は\(v\)を\(D\)進表記して、小数点を\(i\)だけ左に動かし(\(i \lt 0\)なら右)、小数点以下を切り捨てた値であり、\(u_i\)はその\(s_i\)の\(D\)進表記したものの小数点を\(i\)だけ右(\(i \lt 0\)なら左)に動かした値になる。\(w_i\)は\(D_i\)の中で\(u_i\)より1つ大きいものとなる。
具体例を挙げて説明すると、\(v = 123.4\)、\(D = 10\)、\(i = 1\)とすると、\(s_1 = 12\)、\(t_1 = 13\)、\(u_1 = 120\)、\(w_1 = 130\)となる。\(D_1\)の集合は10の倍数で\(120\)と\(130\)以外の値が\(123.4\)により近いことはない、ということが分かるだろう。
さて、この集合\(D_i\)がなんの役に立つかというと、長さに関わってくる。というのは、直感的に\(D_i\)と\(D_{i-1}\)を比較すると後者の方がより細かい刻みを表しているので、前者の方が長さが短くなることが予想される。もうすこし正確に言えば、ある値\(v\)の周辺で\(D_i\)と\(D_{i-1}\)の各要素を比較したら前者の長さが後者のものより長くなることはない。
これも原論文の\(\S\)6で厳密に定式化されているが、ここでは具体例を考えれば十分だろう。たとえば\(D=10\)としたときに\(v = 123.4\)に近い\(D_1\)の要素は\(120\)と\(130\)であった。これらは長さが\(2\)である。一方\(D_0\)で近い可能性がある2つの値は\(123\)と\(124\)で、こちらは長さが\(3\)となる。もちろん\(v = 120.3\)のようにキリがよければ\(D_0\)の\(v\)に近い要素も\(120\)と長さ\(2\)になるが、\(120\)は\(D_1\)の要素でもあるので\(D_1\)の要素より短くなることはない。
\(R_v\)と\(D_i\)の積
ここまで説明すると、この浮動小数点数の文字列化の問題はつぎのように言いかえられることが分かる。まずは\(M=1\)とする。
浮動小数点数\(v\)が与えられたときに、その\(v\)が代表する区間\(R_v\)と集合\(D_i = \{d D^i\}\)の積を\(R_i = R_v \cap D_i\)とする8。空集合でない\(R_i\)のうち、\(i\)がもっとも大きなものを求めたい。
\(i\)が最大の空でない\(R_i\)が求まれば、そのなかで\(v\)にもっとも近い値が\(d_v\)になる。\(M=2\)については、\(d_v\)の長さが\(1\)だったときに必要なら\(D_{i-1}\)も考慮に入れればよい。
例として仮数部が2ビットの浮動小数点数を考え\(v = 96.0, R_v = \left[ 88, 104 \right]\)を考えてみよう。\(i = 0, 1, 2, 3\)について\(R_i\)を調べてみるとつぎのようになる。
\[\begin{align} R_0 &= \{ 88, 89, \ldots, 104 \} \\ R_1 &= \{ 90, 100 \} \\ R_2 &= \{ 100 \} \\ R_3 &= \emptyset \\ \end{align}\]この例では、\(R_2\)が空集合ではなくかついちばん短い要素を持つので、\(M=1\)の場合は\(d_v = 100\)となる。\(M=2\)の場合は\(R_0\)も調べ、このケースでは\(96\)が一番近いので\(96\)が選ばれる。
さて、この\(R_2\)のような集合を\(v\)に対して求めていきたいわけだが、じつは以下がなりたつ9。
\(k\)を\(D^k \ge \left\| R_v \right\| \gt D^{k+1}\)を満たす整数とすると、このような\(k\)は唯一でかつ\(R_k\)はすくなくとも1つの要素を持ち、\(R_{k+1}\)はせいぜい1つの要素を持つ。
したがって、通常は\(R_k\)と\(R_{k+1}\)を調べればよいし、\(M=2\)でかつ\(d_v\)の長さが\(1\)になりそうな場合はそれに加えて\(R_{k-1}\)を調べればよい。さらに、このような\(k\)は\(k = \lfloor \log_D \left\| R_v \right\| \rfloor\)と計算で求められる。
ここで、さきほどの\(v = 96\)の例で\(k\)を計算すると\(\lfloor \log_{10} 16 \rfloor = 1\)なので、\(M=1\)なら\(R_1\)と\(R_2\)だけ、\(M=2\)なら\(R_0\)も調べればよいことがわかる。
いくつかの変数の導入
次節からはアルゴリズムの詳細を見ていくが、簡単のために、この\(k\)をつかってあらかじめつぎの変数を導入しておく。
\[\begin{align} &K_{\min} = k\text{の取りうる最小値}\\ &K_{\max} = k\text{の取りうる最大値} \\ &k' = k + 1 \\ &s = s_k,\quad t = t_k,\quad u = u_k,\quad w = w_k \\ &s' = s_{k'}, \quad t' = t_{k'}, \quad u' = u_{k'}, \quad w' = w_{k'} \end{align}\]この変数をつかうと、\(u\)と\(w\)の定義から、つぎのことがいえる。
\(u \in R_k\)もしくは\(w \in R_k\)のどちらかもしくは両方がなりたつ。また\(R_{k'} = \emptyset\)、\(R_{k'} = \{u'\}\)もしくは\(R_{k'} = \{w'\}\)のいずれかである。
アルゴリズムの詳細
- \(s \ge D^M\)の場合
- これが何を意味するかというと、\(s\)と\(t\)どちらかの長さは\(M\)より大きくなる、ということである。たとえば\(M = 1, s = 10, t = 11\)もしくは\(M = 2, s = 999, t = 1000\)を考えれば分かるだろう。\(k-1\)を考えなければならないのは長さが\(M\)以下でより\(u\)や\(w\)よりも\(v\)に近い値が表せるときだが、このケースでは\(u_{k-1}\)も\(w_{k-1}\)も長さが\(M\)より大きくなるか、あるいは\(u, w\)のいずれかと一致してしまう10。したがって、\(k-1\)のケースは考える必要がない。
- \(R_{k'} \ne \emptyset\)の場合
- \(R_{k'}=\{u'\}\)もしくは\(R_{k'}=\{w'\}\)となる
- \(u', w'\)は\(u, w\)よりも長さが短いかもしくは\(u, w\)と一致するので、\(u', w'\)の2つのどちらか\(R_v\)に含まれる方が\(d_v\)になる
- \(R_{k'} = \emptyset\)の場合
- 前節で述べたように\(u \in R_k\)もしくは\(w \in R_k\)が成り立つので、このどちらかが\(d_v\)になる
- まとめ: \(s \ge D^M\)のとき\(u' \in R_v\)もしくは\(w' \in R_v\)なら、それぞれ\(d_v = u'\)、\(d_v=w'\)となる。\(u', w' \notin R_v\)のときは\(d_v = u\)もしくは\(d_v = w\)となる。
- \(D \le s \lt D^M\)の場合
- これは\(M=1\)のときは成立しないので\(M=2\)としてよい
- この場合は\(s, t\)の長さが\(1\)もしくは\(2\)になる。また両方の長さが\(1\)になることはない。\(s = 10, t = 11\)や\(s = 51, t = 52\)を考えれば分かるだろう。このケースも先ほどと同様に\(k-1\)を考える必要はない。なぜなら\(s_{k-1}\)も\(t_{k-1}\)も長さが\(3\)以上になるか、あるいは\(s\)や\(t\)と一致するからである。
- また、このとき、\(k + 1\)すなわち\(s', t'\)を考える必要もない。なぜなら\(u', w'\)が\(u, w\)より\(v\)に近いことはあり得ないし、長さが短くなったとしても\(1\)になるので、\(M=2\)の場合は\(v\)により近い\(u\)や\(w\)が選ばれるからである。
- まとめ: \(D \le s \lt D^M\)のとき\(d_v = u\)もしくは\(d_v = w\)
- \(s \lt D\)の場合
- このとき\(u, w\)の長さは\(1\)になる。\(M=1\)ならこれが長さ\(M\)以下でもっとも\(v\)に近い値になる。
- \(M=2\)のときは\(u_{k-1}, w_{k-1}\)の長さが\(1\)もしくは\(2\)になり、より\(u, w\)よりも\(v\)から遠くはならないので\(d_v = u_{k-1}\)もしくは\(d_v = w_{k-1}\)
- まとめ: \(M=1\)なら\(d_v = u\)もしくは\(d_v = w\)、\(M=2\)なら\(d_v = u_{k-1}\)もしくは\(d_v = w_{k-1}\)
疑似コード
以上のアルゴリズムを疑似コードにするとつぎのようになる。ただし、\(s\)を計算するまえに\(s \lt D\)の条件分岐をしたいという要請から\(v = c 2^q\)と表したときに、\(s \lt D \Leftrightarrow c \lt C_{\text{tiny}}\)となる\(C_{\text{tiny}}\)をあらかじめ計算しておく11。なお\(c\)と\(q\)はそれぞれ整数で浮動小数点数の仮数部のように\(c = 1\ldots\)という形式を満たしている。さらに\(v_\text{tiny} = C_\text{tiny}2^Q_\min\)とする。ここで\(Q_\min\)は\(fp\)で\(q\)が取り得る値の最小値。
また、\(s_{k-1} = s_k(vD)\)かつ\(u_{k-1}=u_k(vD)\)から、疑似コードでは\(v \lt v_\text{tiny}\)のときに\(v\)に\(vD\)を代入して計算してさいごに指数部を\(1\)減らす、という簡略化を行っている。
\[\begin{align} & \text{if} \, M = 2 \land v \lt v_\text{tiny} \, \text{then}\\ & \quad v \gets v D, \Delta k \gets -1 \\ & \text{else} \\ & \quad \Delta k \gets 0 \\ & \text{fi} \\ & c, q, k, s \text{を計算する} \\ & \text{if}\, s \ge D^M\,\text{then}\\ & \quad k' \gets k + 1, s' \gets s // D, u' \gets s' D^{k'}, w' \gets (s' + 1)D^{k'} \\ & \quad \text{if}\, u' \in R_v \, \text{then return}\, u' \\ & \quad \text{if}\, w' \in R_v \, \text{then return}\, w' \\ & \text{fi} \\ & u \gets sD^k, w \gets (s + 1) D^k \\ & \text{if}\, u \in R_v \land w \notin R_v\, \text{then} \\ & \quad \text{return}\, uD^{\Delta k}\, \\ & \text{fi} \\ & \text{if}\, u \notin R_v \land w \in R_v\, \text{then} \\ & \quad \text{return}\, wD^{\Delta k}\, \\ & \text{fi} \\ & \text{if}\, v - u \lt w - v\, \text{then} \\ & \quad \text{return}\, uD^{\Delta k}\, \\ & \text{fi}\\ & \text{if}\, v - u \gt w - v\, \text{then} \\ & \quad \text{return}\, wD^{\Delta k}\, \\ & \text{fi}\\ & \text{if}\, s \,\text{が偶数 then} \\ & \quad \text{return}\, uD^{\Delta k}\, \\ & \text{fi} \\ & \text{return}\, wD^{\Delta k} \\ \end{align}\]なお、\(//\)は整数除算で余りを切り捨てる操作を表す。
このアルゴリズムをそのまま実装すると任意精度の計算(JavaのBigIntergerなど)を必要とするので、さらに改良してビット演算だけで行う方法が論文に紹介されている。また、このアルゴリズムはOpenJDKのDouble#toString()の実装のもとになっているのでコードを読んでもいいだろう。
蛇足
この論文に興味を持ったきっかけはPrinting double aka the most difficult problem in computer scienceという記事だった。記事の内容は率直に言って鼻持ちならない内容で他人のStackOverflowの回答を貶していく、という控え目にいってもこの作者と一緒に働きたくないな、というものだった。タイトルのdoubleの文字列化をコンピュータ科学で最も難しい問題と臆面もなく言い放つことにも反感を覚えて、論文を手にとった次第だ。
読んだ感想としては依然として「CSで一番難しい問題」とは思えないけれど、OpenJDKの実装にも使われるアルゴリズムを勉強できてよかった、と思う。
ただ、この浮動小数点数の文字列化という問題はかなり恣意的であるように思う。まず有効桁数を気にしない癖に出力がround tripを満たす範囲で短くあってほしい、という状況がよく分からない。実験や数値計算のアプリケーションでデータの再利用を前提とするなら有効桁数は常に気にするし、出力データで正確さを担保したければ記事の冒頭でも書いたように小数点以下17桁まで出力しておけばよい。一方、データの再利用を前提とせずにユーザーに表示するだけ、たとえばBMIの結果を表示する、となったらそれはそれでアプリケーションで適切に有効数字を決められるだろう。
この「いい感じに浮動小数点数を文字列化したい」という問題は、そう考えるとデバッグ用にログする場合くらいしか用途がなさそうで、実際JavaのDouble#toString()はまさにそういう用途だ。そう考えると、解こうとしている問題はかなり限定的で、わざわざがんばって高速化する意味がどれくらいあるかは分からない。
なお、このアルゴリズムの前にも浮動小数点数の文字列化にはいくつもアルゴリズムが提唱されているらしい。それらについては調べていないので、興味のある人はどうぞ調べてみてほしい12。
-
Stackoverflowの回答によると、C++20の
std::formatは{fmt}ライブラリをもとにしており、{fmt}ライブラリは浮動小数点数のフォーマットにDragonboxというライブラリをつかっており、このライブラリの元がこの論文らしい ↩ -
1.2がなぜ有限の2進数で表せないか考えるのは、ちょうどいい算数の問題だろう。一方で有限の2進数はかならず有限の10進数で表せることが分かっている。 ↩ -
ここではほとんどの人間は10進数の方が理解しやすいという前提をおいている。2進数の方が理解しやすいという人に対してはそのまま浮動小数点数のバイナリ表記を表示すればいいので簡単だ。 ↩
-
Schubfachの論文ではとくになんの説明もなしにround tripという用語が使われていた。初出はどこか分からないが往復のことをround tripと呼ぶし英語の表現としては自然なのかもしれない。 ↩
-
When is round-trip floating point radix conversion exact? https://www.johndcook.com/blog/2020/03/16/round-trip-radix-conversion/ ↩
-
率直にいうと、自分はたとえば数値計算で大量の数値を見るならすべての値の桁はそろっていてほしいし、これがどれくらい一般的な要求なのかやや疑問ではある。あと、17桁くらいならいいんじゃないと思ってしまうが、この感覚は一般的ではないのかもしれない。 ↩
-
分かりにくいが原論文がそうなっているので我慢されたい。たとえば\(v = 1.011_2\cdot 2^{-10}\)だったら\(c=101100000_2\)、\(q=-18\)となる ↩
-
なぜ\(R_v\)と同じ\(R\)を使うのが理解に苦しむが原論文がそうしているので混乱を避けるためにもそうする。読者は添字が\(v\)であるか、あるいは整数であるかで判断していただきたい。 ↩
-
詳細はまたも原論文に譲るが、アイディアとしては「鳩の巣原理」にもとづいており、このアルゴリズムをSchubfachと呼ぶのもこの原理の発明者ディリクレのドイツ名Schubfachprinzipに由来するらしい。 ↩
-
たとえば\(M=1\)で\(s_k(v)=10, t_k(v)=11\)となった場合を考えよう。\(s_{k-1}(v)\)と\(s_{k-1}(v)\)は\(v\)の値によるが、\(\{100, 101, 102, \ldots, 110\}\)のどれかであり、両端はそれぞれ\(s_k(v), t_k(v)\)と一致している。したがって\(k-1\)を探す必要はないことが分かる。 ↩
-
詳細はこれも原論文に譲るが、\(C_{\text{tiny}} = \lceil 2^{-Q_\min} D^{K_\min + 1} \rceil\)と表され、\(D=10\)で倍精度浮動小数点の場合は\(C_{\text{tiny}} = \lceil 2^{1074} 10^{-324 + 1} \rceil = 3\)、単精度浮動小数点の場合は\(C_{\text{tiny}} = 8\)となる。これは仮数部の下位2ビットもしくは3ビット以外がすべて0になっている場合なので、非正規化数のうちでもかなり小さい値であることがわかる。 ↩
-
日本語の資料だと浮動小数点数の文字列化(基数変換)という記事にいくつかの論文への参照が載っていた。 ↩