Ubuntu 24.10で日本語句読点が中央に表示される問題とその修正
Ubuntu 24.10で、日本語の読点や句点がつぎのように中央に表示されることがある。どうやら、まわりを日本語以外で囲まれているときに発生するようだ。
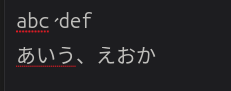
これはテキストエディタ(gnome-text-editor)で自分で入力しても発生するし、ブラウザでこのような文字列を表示するときも発生する。
この問題の修正方法と原因(と思われるもの)を説明する。
環境
- Ubuntu 24.10
- fontconfig 2.15.0-2.2
- language-selector-common 0.227
再現手順
- Ubuntuにログインする
- テキストエディタ(gnome-text-editor)を起動する
- 一行目に
abc、def(読点はU+3001)を入力する - 二行目に
あいう、えおか(読点はU+3001)を入力する
現象
さきほどのスクリーンショットのように読点(U+3001)の字形(glyph)が一行目と二行目で異なるものになる。
修正方法
$HOME/.config/fontconfig/fonts.confに以下のように記述する(ファイルがなければ作成する)<?xml version="1.0"?> <!DOCTYPE fontconfig SYSTEM "urn:fontconfig:fonts.dtd"> <!-- $XDG_CONFIG_HOME/fontconfig/fonts.conf for per-user font configuration --> <fontconfig> <match> <test name="lang" compare="contains"> <string>en</string> </test> <test name="family"> <string>sans-serif</string> </test> <edit name="family" mode="prepend"> <string>Noto Sans</string> </edit> <!-- This entry is necessary to avoid a wrong font is used for a colon in the system clock display. --> <edit name="family" mode="prepend"> <string>Noto Sans Math</string> </edit> <edit name="family" mode="prepend"> <string>Noto Sans CJK JP</string> </edit> </match> </fontconfig>- さきほどの再現手順のステップ#2 - #4を行い、直っていることを確認する
- Ubuntuに再ログインして、問題がなくなっていることを確認する
原因(と思われるもの)
読点(U+3001)の字形はフォントによって異なる。この文字コードはUnicodeの108個目の「CJKの記号及び約物」というブロックに収録されている。名前のとおり、CJKで統合されているので、このユニコードだけを見て、どの言語(文字)の字形を使うべきかは判断できない。
どうやら最近のUbuntu(23.10以降?)ではテキストの言語を判定してそれに合わせてNoto Sansのフォントが選ばれるらしい。読点(U+3001)の周囲が日本語なら、その文字は、日本語のフォント、たとえば”Noto Sans CJK JP”でレンダリングされる。一方、読点の周囲がアルファベットだった場合、そのテキストの言語は英語と判断される。このとき英語のフォント(たとえば”Ubuntu Sans”)はU+3001に対応する字形を持っていない可能性が高く、他のフォントにフォールバックされる。
Ubuntu 24.10では、このフォールバックが発生し、このフォールバック順序は、どうやら/etc/fonts/conf.d/56-language-selector-prefer.confで指定されているらしい。このファイルでは”Noto Sans Mongolian”が”Noto Sans CJK JP”よりも前にあるので、”Noto Sans Mongolian”が使われる。実際に”Noto Sans Mongolian”のU+3001の字形はスクリーンショットで見たようなものになる(参照:On Mongolian punctuation marks)。
では、どうやって修正するか?手っ取り早いのは、フォントの優先順を変更して、好みのU+3001の字形を含むフォントを前に持ってくることだ。実際に、GitHubのissueについたコメントでは/etc/fonts/local.confを書いて、”Noto Sans”の次に自分の使いたいフォントを指定する方法が紹介されている。ただし、これを行うとつぎのスクリーンショットのように、システムバーの時計の表示がおかしくなり、真ん中のコロンが全角(?)のようになってしまう。
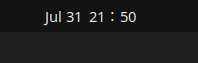
これの修正のために/etc/fonts/conf.d/56-language-selector-prefer.confを直接書き換える方法が同じissueのコメントで提案されているが、これはこれで、バージョンアップで上書きされる可能性があり、望ましくない。
自分の修正は1つめの修正に近いが、つぎの違いがある。
$HOME/.config/fontconfig以下なので、自分以外のユーザーには影響がない- “Noto Sans Math”を追加することでシステムバーの時計表示の不具合を回避
- 言語を”en”に限定することで、影響を小さめにしている
付録
最後に、調査をする上で便利だったコマンドを紹介する。
FC_DEBUG
環境変数FC_DEBUGを指定してアプリケーションを起動すると、標準出力にデバッグ情報が出力される。たとえば、この環境変数つきでgnome-text-editorを起動して読点(U+3001)を入力するとつぎのように出力され、どのフォントが使われているか分かる。
$ FC_DEBUG=1 gnome-text-editor
...
Match Pattern has 29 elts (size 32)
family: "Noto Sans Mongolian"(s) "Noto Sans"(w) "Noto Sans Adlam"(w) ...
familylang: "en"(s) "en-us"(w)
stylelang: "en"(s) "en-us"(w)
fullnamelang: "en"(s) "en-us"(w)
...
fc-match
fc-matchというコマンドを使うと、特定のフォントファミリーや特定の言語のときに使われるフォントの優先順位を見ることができる。
$ fc-match -s sans-serif:en
NotoSans-Regular.ttf: "Noto Sans" "Regular"
NotoSansAdlam-Regular.ttf: "Noto Sans Adlam" "Regular"
NotoSansArabic-Regular.ttf: "Noto Sans Arabic" "Regular"
NotoSansArmenian-Regular.ttf: "Noto Sans Armenian" "Regular"
...
さきに書いた修正方法を適用したあとはつぎのようになる。
NotoSans-Regular.ttf: "Noto Sans" "Regular"
NotoSansMath-Regular.ttf: "Noto Sans Math" "Regular"
NotoSansCJK-Regular.ttc: "Noto Sans CJK JP" "Regular"
NotoSansAdlam-Regular.ttf: "Noto Sans Adlam" "Regular"
...